Source: http://musingsaboutlibrarianship.blogspot.my/2014/06/8-surprising-things-i-learnt-about.html
8 surprising things I learnt about Google Scholar
Google Scholar is increasingly becoming a subject that an academic librarian cannot afford to be ignorant about.
![]()
"Google Scholar supports Highwire Press tags (e.g., citation_title),
Eprints tags (e.g., eprints.title), BE Press tags (e.g.,
bepress_citation_title), and PRISM tags (e.g., prism.title). Use Dublin
Core tags (e.g., DC.title) as a last resort - they work poorly for
journal papers because Dublin Core doesn't have unambiguous fields for
journal title, volume, issue, and page numbers." - right from horse's mouthAlso this
Other interesting points
Her response in my admittedly limited experience when asking questions
about institutional repository items presence in Google Scholar is
amazingly fast.
Musings about librarianship: 8 surprising things I learnt about Google Scholar
8 surprising things I learnt about Google Scholar
Google Scholar is increasingly becoming a subject that an academic librarian cannot afford to be ignorant about.
Various surveys have shown usage of Google Scholar is rising among researchers, particularly beginning and intermediate level researchers. Our own internal statistics such as link resolver statistics and views of Libguides on Google Scholar, tell a similar story.
Of course, researchers including librarians have taken note of this and
there is intense interest in details about Google Scholar.
I noticed for example in April....
there is intense interest in details about Google Scholar.
I noticed for example in April....
More recently there was also the release of a Google Scholar Digest that is well worth reading.
Sadly Google Scholar is something I've argued that libraries don't have any competitive advantage in, because we are not paying customers, so Google does not owe us any answers, so learning about it is mostly trial and error.
Recently, I've been fortunate to be able to encounter and study Google Scholar from different angles at work including
a) Work on discovery services - lead me to study the differences and similarities of Google Scholar and Summon (also on systematic reviews). Also helping test and setting up the link resolver for Google Scholar.
b) Work on bibliometrics team - lead me to study the strengths and
weakness of Google Scholar and related services such as Google
Citations and Google Scholar Metrics vs Web of Science/Scopus as a
citation tool.
weakness of Google Scholar and related services such as Google
Citations and Google Scholar Metrics vs Web of Science/Scopus as a
citation tool.
c) Most recently, I've was studying a little how entries in our
Institutional repositories were indexed and displayed in Google Scholar.
Institutional repositories were indexed and displayed in Google Scholar.
I would like to set out 8 points/features on Google Scholar that
surprised me when I learnt about them, I hope they are things you find
surprising or interesting as well.
1. Google does not include full text of articles but Google Scholar does
I always held the idea without considering it too deeply was that Google
had everything or mostly everything in Google Scholar but not
viceversa.
In the broad sense this is correct, search any journal article by title
and chances are you will see the same first entry going to the article
on the publisher site in both Google and Google Scholar.
This also reflects the way we present Google Scholar to students. We
imply that Google Scholar is a scope limited version of Google, and we
say if you want to use a Google service, at least use Google Scholar,
which does not include non-scholarly entries like Wikipedia, blog
entries unlike in Google.
All this is correct, except the main difference between Google Scholar
and Google, is while both allow you to find articles if you search by
title, only Google Scholar includes full-text in the index.
Why this happens is that the bots from Google Scholar are given the
rights by publishers like Elsevier, Sage to index the full-text of
paywalled articles on publisher owned platform domains, while Google
bots can only get at whatever is public, basically title and abstracts.
(I am unsure if the bots harvesting for Google and Google Scholar are
actually different, but the final result is the same).
I suppose some of you will be thinking this is obvious, but it wasn't to
me. Until librarians started to discuss a partnership Elsevier
announced with Google in Nov 2013.
![]()
Initially I was confused, didn't Google already index scholarly articles? But reading it carefully, you see it talked about full-text
The FAQ states this explicitly.
![]()
A sidenote, this partnership apparently works such that if you opt-in,
your users using Google within your internal ip range will be able to
do full-text article matches (within your subscription). We didn't turn
it on here, so this is just speculation.
2. Google Scholar has a very comprehensive index , great recall but poor precision for systematic reviews.
I am not a medical librarian, but I have had some interest in systematic
reviews because part of my portfolio includes Public Policy which is
starting to employ systematic reviews. Add my interest in Discovery
services meant I do have a small amount of interest in how discovery systems are similar and different to Google.
In particular "Google Scholar as replacement for systematic literature searches: good relative recall and precision are not enough" was a very enlightening paper that drilled deep into the capabilities of Google Scholar.
Without going into great detail (you can also read Is Summon alone good enough for systematic reviews? Some thoughts),
the paper points out that while the index of Google Scholar is
generally good enough to include almost all the papers eventually found
for systematic reviews (verified by searching for known titles) , the
lack of precision searching capabilities means one could never even find
the papers in the first place when actually doing a systematic review.
This is further worsened by the fact that Google Scholar, like Google actually only shows a maximum of 1,000 results anyway
so even if you were willing to spend hours on the task it would be a
futile effort if the number of results shown are above 1,000.
Why lack of precision searching? See next point.
3. Google Scholar has 256 character limit, lacking truncation and nesting of search subexpressions for more than 1 level.
Again Google Scholar as replacement for systematic literature searches: good relative recall and precision are not enough gets credit from me for the most detailed listing of strengths and weaknesses of Google Scholar.
Some librarians seem to sell Google and Google Scholar short. Years
ago, I heard of librarians who in an effort to discourage Google use,
tell students Google doesn't do Boolean OR for example, which of course
isn't the case.
Google and Google Scholar does "implied AND" and of course you could always add "OR", As far as I can tell the undocumented Around function doesn't work for Google Scholar though.
The main issue with Google Scholar that makes precision searching hard is
a) Lack of truncation
b) Unable to turn off autostemming - (Verbatim mode available only in Google, not sure if + operator works for Google Scholar, but it is depreciated for Google)
These are well known.
But I think lesser known is that there is a character limit for search
queries in Google Scholar of 256. Apparently if you go beyond, it will
silently drop the extra terms without warning you. Typical searches of
course won't go beyond 256 characters, but ultra precise systematic
review queries might of course.
Another thing that is is interesting to me is the paper I believe states
that nested boolean operators beyond one level will fail.
4. Google Scholar harvests at the article level, hence it is difficult for them to give coverage lists.
Think many people know that Google Scholar's index is constructed very
differently from databases in that it crawls page by page, pulling in
content it considers Scholarly at the article level.
This meant that multiple versions of the same article could be pulled
into Google Scholar and combined, so for example it could grab copies
from
![]()
I knew this, but only fairly recently it dawned on me this is the reason
for why Google Scholar does not have a coverage list of publication
with coverage dates.
Essentially they pull items at the article level, so there is no easy
way to succinctly summarise their coverage at the journal title.
Eg. Say there is a journal publisher that for whatever reason bars them
from indexing, they could still have some articles with varying coverage
and gaps by harvesting individual articles from institutional
repositories that may have some of the articles from the journal.
Even if they had the rights to harvest all the content from say Wiley,
the harvester might still miss out a few articles because of poor link
structure etc.
So they would in theory have coverage that could be extremely spotty,
with say an article or 2 in a certain issue, a full run for some years
etc.
As a sidenote, I can't help but compare this to Summon's stance that
they index at the journal title level rather than database level, except
Google Scholar indexes at a even lower level at the article level.
Of course in theory Google Scholar could list the publisher domains that were indexed?
That said, I suspect based on some interviews by Anurag Acharya when
asked this question, fundamentally Google doesn't even think the
coverage data is useful to most searchers. I believe he notes, that even
though databases with large indexes have sources listed, it still
provides little guidance on what to use and most guides recommend just
searching all of them anyway.
Other semi-interesting things include
5. You can't
use Site:institutionalrepositoryurl in Google Scholar to estimate number
of entries in your Institutional repository indexed in Google Scholar
surprised me when I learnt about them, I hope they are things you find
surprising or interesting as well.
1. Google does not include full text of articles but Google Scholar does
I always held the idea without considering it too deeply was that Google
had everything or mostly everything in Google Scholar but not
viceversa.
In the broad sense this is correct, search any journal article by title
and chances are you will see the same first entry going to the article
on the publisher site in both Google and Google Scholar.
This also reflects the way we present Google Scholar to students. We
imply that Google Scholar is a scope limited version of Google, and we
say if you want to use a Google service, at least use Google Scholar,
which does not include non-scholarly entries like Wikipedia, blog
entries unlike in Google.
All this is correct, except the main difference between Google Scholar
and Google, is while both allow you to find articles if you search by
title, only Google Scholar includes full-text in the index.
Why this happens is that the bots from Google Scholar are given the
rights by publishers like Elsevier, Sage to index the full-text of
paywalled articles on publisher owned platform domains, while Google
bots can only get at whatever is public, basically title and abstracts.
(I am unsure if the bots harvesting for Google and Google Scholar are
actually different, but the final result is the same).
I suppose some of you will be thinking this is obvious, but it wasn't to
me. Until librarians started to discuss a partnership Elsevier
announced with Google in Nov 2013.
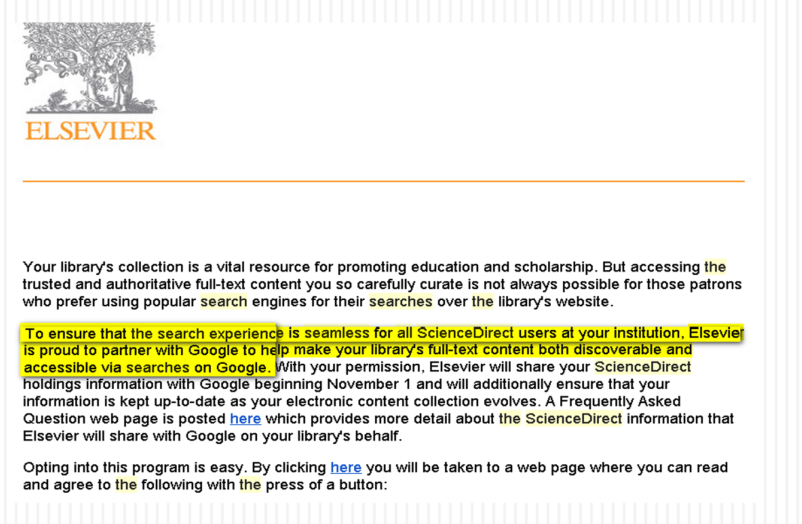
Initially I was confused, didn't Google already index scholarly articles? But reading it carefully, you see it talked about full-text
The FAQ states this explicitly.

A sidenote, this partnership apparently works such that if you opt-in,
your users using Google within your internal ip range will be able to
do full-text article matches (within your subscription). We didn't turn
it on here, so this is just speculation.
2. Google Scholar has a very comprehensive index , great recall but poor precision for systematic reviews.
I am not a medical librarian, but I have had some interest in systematic
reviews because part of my portfolio includes Public Policy which is
starting to employ systematic reviews. Add my interest in Discovery
services meant I do have a small amount of interest in how discovery systems are similar and different to Google.
In particular "Google Scholar as replacement for systematic literature searches: good relative recall and precision are not enough" was a very enlightening paper that drilled deep into the capabilities of Google Scholar.
Without going into great detail (you can also read Is Summon alone good enough for systematic reviews? Some thoughts),
the paper points out that while the index of Google Scholar is
generally good enough to include almost all the papers eventually found
for systematic reviews (verified by searching for known titles) , the
lack of precision searching capabilities means one could never even find
the papers in the first place when actually doing a systematic review.
This is further worsened by the fact that Google Scholar, like Google actually only shows a maximum of 1,000 results anyway
so even if you were willing to spend hours on the task it would be a
futile effort if the number of results shown are above 1,000.
Why lack of precision searching? See next point.
3. Google Scholar has 256 character limit, lacking truncation and nesting of search subexpressions for more than 1 level.
Again Google Scholar as replacement for systematic literature searches: good relative recall and precision are not enough gets credit from me for the most detailed listing of strengths and weaknesses of Google Scholar.
Some librarians seem to sell Google and Google Scholar short. Years
ago, I heard of librarians who in an effort to discourage Google use,
tell students Google doesn't do Boolean OR for example, which of course
isn't the case.
Google and Google Scholar does "implied AND" and of course you could always add "OR", As far as I can tell the undocumented Around function doesn't work for Google Scholar though.
The main issue with Google Scholar that makes precision searching hard is
a) Lack of truncation
b) Unable to turn off autostemming - (Verbatim mode available only in Google, not sure if + operator works for Google Scholar, but it is depreciated for Google)
These are well known.
But I think lesser known is that there is a character limit for search
queries in Google Scholar of 256. Apparently if you go beyond, it will
silently drop the extra terms without warning you. Typical searches of
course won't go beyond 256 characters, but ultra precise systematic
review queries might of course.
Another thing that is is interesting to me is the paper I believe states
that nested boolean operators beyond one level will fail.
4. Google Scholar harvests at the article level, hence it is difficult for them to give coverage lists.
Think many people know that Google Scholar's index is constructed very
differently from databases in that it crawls page by page, pulling in
content it considers Scholarly at the article level.
This meant that multiple versions of the same article could be pulled
into Google Scholar and combined, so for example it could grab copies
from
- the main publisher site (eg Sage)
- an aggregator site or citation only site
- a Institutional repository
- even semi-legal copies on author homepage, Researchgate, Academia.edu etc
All these versions are auto-combined.

I knew this, but only fairly recently it dawned on me this is the reason
for why Google Scholar does not have a coverage list of publication
with coverage dates.
Essentially they pull items at the article level, so there is no easy
way to succinctly summarise their coverage at the journal title.
Eg. Say there is a journal publisher that for whatever reason bars them
from indexing, they could still have some articles with varying coverage
and gaps by harvesting individual articles from institutional
repositories that may have some of the articles from the journal.
Even if they had the rights to harvest all the content from say Wiley,
the harvester might still miss out a few articles because of poor link
structure etc.
So they would in theory have coverage that could be extremely spotty,
with say an article or 2 in a certain issue, a full run for some years
etc.
As a sidenote, I can't help but compare this to Summon's stance that
they index at the journal title level rather than database level, except
Google Scholar indexes at a even lower level at the article level.
Of course in theory Google Scholar could list the publisher domains that were indexed?
That said, I suspect based on some interviews by Anurag Acharya when
asked this question, fundamentally Google doesn't even think the
coverage data is useful to most searchers. I believe he notes, that even
though databases with large indexes have sources listed, it still
provides little guidance on what to use and most guides recommend just
searching all of them anyway.
Other semi-interesting things include
- Google Scholar tries to group different "manifestations" and all cites are to the this group
- Google Scholar uses automated parsers to try to figure out author
and title, while may lead to issues of ghost authors, though this
problem seems to be mostly resolved [paywall source]
5. You can't
use Site:institutionalrepositoryurl in Google Scholar to estimate number
of entries in your Institutional repository indexed in Google Scholar
Because of #4 , we knew it was unlikely everything in our institutional repository would be in Google Scholar.
I was naive and ignorant to think though one could estimate the amount
indexed in our institutional repository in Google scholar by using the
site operator.
I planned to do say Site:http://dash.harvard.edu in Google Scholar and look at the number of results. That should work by returning all results from the site right?
![]()
Does Harvard's institutional repository only have 4,000+ results in Google Scholar?
Even leaving aside the weasel word "about", sadly it does not work as you might expected. In the official help files it
is stated this won't work and the best way to try to see if there is an
issue is to randomly sample entries from your institutional repository.
Why? Invisible institutional repositories: Addressing the low indexing ratios of IRs in Google Scholar has the answer.
First, we already know when there are multiple versions, Google Scholar
will select a primary document to link to. That is usually the one at
the publisher site. The remaining ones that are not primary will be
under the "All X versions".
![]()
According to Invisible institutional repositories: Addressing the low indexing ratios of IRs in Google Scholar., the site operator will only show up articles where the copy in your institutional repository is the primary document (the one that the title links to in Google Scholar, rather than those under "All X versions")
Perhaps one of the reasons I was mislead was I was reading studies like this calculating and comparing Google Scholar indexing ratios.
![]()
These studies, calculate a percentage based on number of results found
using the site:operator as a percentage of total entries in the
Institutional repository.
These studies are useful as a benchmark when studied across institutional repositories of course.
But I think assuming site:institututionalrepository shows only
primary documents, this also means the more unique content your
Institutional repository has (or for some reason the main publisher copy
isn't indexed or recognised as the main entry), the higher your Google Scholar indexing ratio will be.
Some institutional repositories contains tons of metadata without
full-text (obtained from Scopus etc), and these will lower the Google
Scholar indexing ratio, because they will be typically under "all x
variants" and will be invisible to Site:institutionalrepositoryurl
Other interesting points/implications
![]()
Seems to me this also implies most users from Google Scholar won't see
your fancy Institutional repository features but will at best be sent to
the full-text pdf directly, unless they bother to look under "All X
versions"
I was naive and ignorant to think though one could estimate the amount
indexed in our institutional repository in Google scholar by using the
site operator.
I planned to do say Site:http://dash.harvard.edu in Google Scholar and look at the number of results. That should work by returning all results from the site right?
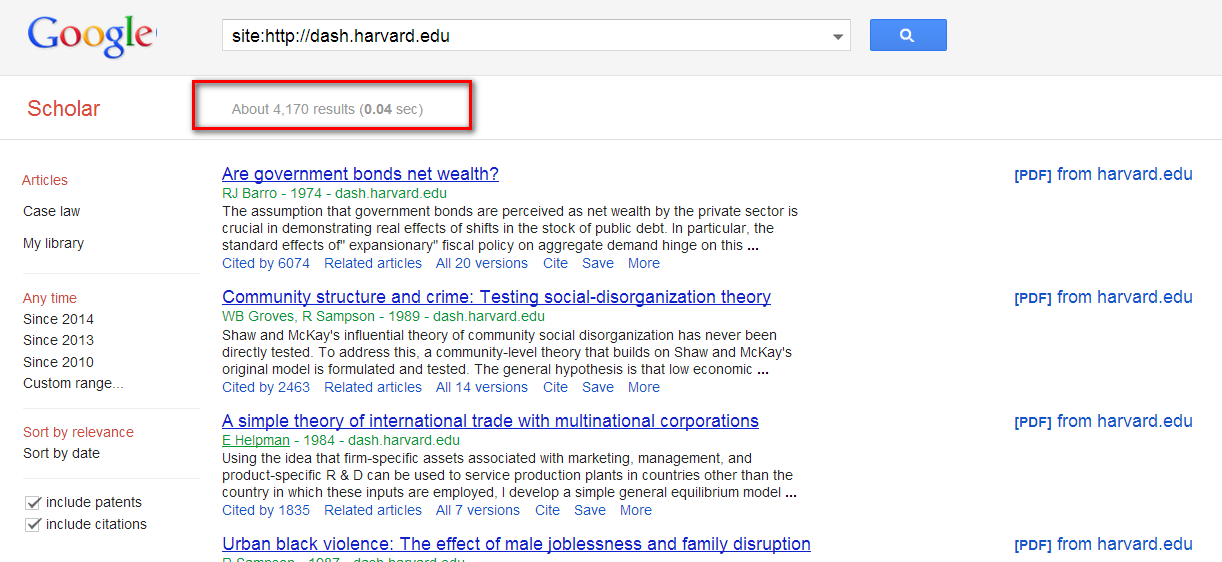
Does Harvard's institutional repository only have 4,000+ results in Google Scholar?
Even leaving aside the weasel word "about", sadly it does not work as you might expected. In the official help files it
is stated this won't work and the best way to try to see if there is an
issue is to randomly sample entries from your institutional repository.
Why? Invisible institutional repositories: Addressing the low indexing ratios of IRs in Google Scholar has the answer.
First, we already know when there are multiple versions, Google Scholar
will select a primary document to link to. That is usually the one at
the publisher site. The remaining ones that are not primary will be
under the "All X versions".

According to Invisible institutional repositories: Addressing the low indexing ratios of IRs in Google Scholar., the site operator will only show up articles where the copy in your institutional repository is the primary document (the one that the title links to in Google Scholar, rather than those under "All X versions")
Perhaps one of the reasons I was mislead was I was reading studies like this calculating and comparing Google Scholar indexing ratios.

These studies, calculate a percentage based on number of results found
using the site:operator as a percentage of total entries in the
Institutional repository.
These studies are useful as a benchmark when studied across institutional repositories of course.
But I think assuming site:institututionalrepository shows only
primary documents, this also means the more unique content your
Institutional repository has (or for some reason the main publisher copy
isn't indexed or recognised as the main entry), the higher your Google Scholar indexing ratio will be.
Some institutional repositories contains tons of metadata without
full-text (obtained from Scopus etc), and these will lower the Google
Scholar indexing ratio, because they will be typically under "all x
variants" and will be invisible to Site:institutionalrepositoryurl
Other interesting points/implications
- Visibility of your institutional repository will be low if all you
have is post/preprints of "normal" articles where publisher sites are
indexed. - If the item is not free on the main publisher site and you have the
full-text uploaded on your institutional repository Google scholar will
show on the right a [Pdf ] from yourdomain

Seems to me this also implies most users from Google Scholar won't see
your fancy Institutional repository features but will at best be sent to
the full-text pdf directly, unless they bother to look under "All X
versions"
- If the item lacks an abstract Google Scholar can identify, it will tend to have a [Citation] tag.
6. Google Scholar does not support OAI-PMH, and use Dublin Core tags (e.g., DC.title) as a last resort.
"Google Scholar supports Highwire Press tags (e.g., citation_title),
Eprints tags (e.g., eprints.title), BE Press tags (e.g.,
bepress_citation_title), and PRISM tags (e.g., prism.title). Use Dublin
Core tags (e.g., DC.title) as a last resort - they work poorly for
journal papers because Dublin Core doesn't have unambiguous fields for
journal title, volume, issue, and page numbers." - right from horse's mouth
Other interesting points
- "New papers are normally added several times a week; however,
updates of papers that are already included usually take 6-9 months.
Updates of papers on very large websites may take several years, because
to update a site, we need to recrawl it" - To be indexed you need to have the full text OR (bibliometric data AND abstract)
- Files cannot be more than 5 MB, so books, dissertations should be uploaded to Google Books.
7. Despite the meme going on that Google and especially Google
Scholar (an even smaller almost microscopic team within Google) does not
respond to queries, they actually do respond at least for certain types
of queries.
Scholar (an even smaller almost microscopic team within Google) does not
respond to queries, they actually do respond at least for certain types
of queries.
We know the saying if you are not paying you are the product. Google and
Google Scholar have a reputation for having poor customer service.
Google Scholar have a reputation for having poor customer service.
But here's the point I missed, when libraries put on their hats as
institutional repository manager, their position with respect to Google
is different and you can get responses.
institutional repository manager, their position with respect to Google
is different and you can get responses.
In particular, there is a person at Google Darcy Dapra - Partner Manager, Google Scholar at Google, who is tasked to do outreach for library institutional repositories and publishers.
She has given talks to librarians managing institutional repositories as well as publishers in relation to indexing issues in Google Scholar.
She has given talks to librarians managing institutional repositories as well as publishers in relation to indexing issues in Google Scholar.
Her response in my admittedly limited experience when asking questions
about institutional repository items presence in Google Scholar is
amazingly fast.
8. Google Scholar Metrics - you can find H-index scores for items not ranked in the top 100 or 20.
Google Scholar Metrics which ranks publications is kinda comparable to
Journal Impact factor or other journal level metrics like SNIP, SJR, eigenfactor etc
First time I looked at it, I saw you could only pull out the top 100 ranked publications by languages (excluding English).
For English, at the main category and subcategories it will show the top 20 entries.
![]()
I used to think that was all that was possible, if the publication was
not in the top 20 of each English Category or Subcategory, you couldn't
find a metric for the publication.
Apparently, not as you can search by journal titles. Maybe obvious but I totally missed this.
![]()
As far as I can tell entries 7 & 8 above are not in the top 20 of
any category or sub-category yet there is a H5 index for this.
How is this useful? Though we would frown on improper use of journal
level metrics, I have often encountered users who want some metric, any
metric for a certain journal (presumably they published in it) and they
are not going to take "this isn't the way you use it for research
assessment" anyway.
When you exhaust all the usual suspects (JCR, SNIP, Scimago rank etc), you might want to give this a try.
Other interesting points
Google Scholar Metrics which ranks publications is kinda comparable to
Journal Impact factor or other journal level metrics like SNIP, SJR, eigenfactor etc
First time I looked at it, I saw you could only pull out the top 100 ranked publications by languages (excluding English).
For English, at the main category and subcategories it will show the top 20 entries.

Top 20 ranked publications for Development Economics
I used to think that was all that was possible, if the publication was
not in the top 20 of each English Category or Subcategory, you couldn't
find a metric for the publication.
Apparently, not as you can search by journal titles. Maybe obvious but I totally missed this.
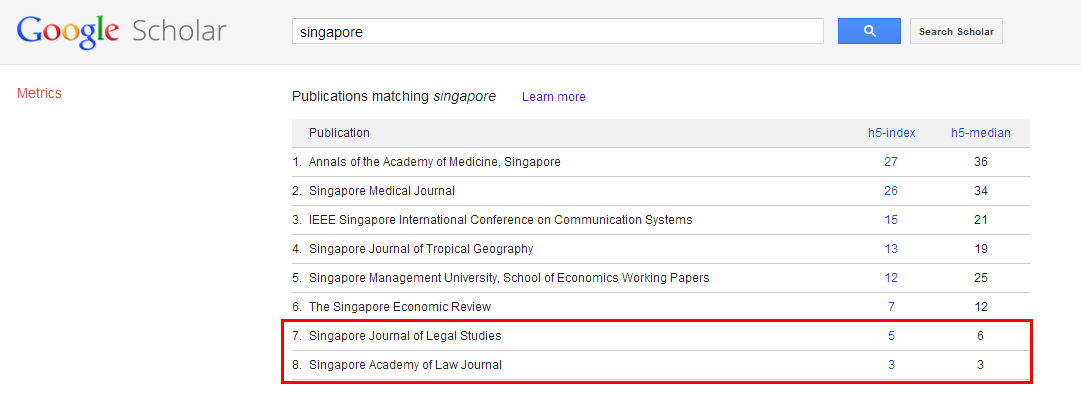
As far as I can tell entries 7 & 8 above are not in the top 20 of
any category or sub-category yet there is a H5 index for this.
How is this useful? Though we would frown on improper use of journal
level metrics, I have often encountered users who want some metric, any
metric for a certain journal (presumably they published in it) and they
are not going to take "this isn't the way you use it for research
assessment" anyway.
When you exhaust all the usual suspects (JCR, SNIP, Scimago rank etc), you might want to give this a try.
Other interesting points
- There doesn't seem to be a fixed period of updates (e.g Yearly)
- Some Subject repositories like arXiv are ranked though at more granular levels eg arXiv Materials Science (cond-mat.mtrl-sci)
- Suggested reading
Conclusion
Given this is Google Scholar, where people figure things out by trial
and error and/or things are always in flux, it's almost certain I got
some things wrong.
Do let me know any errors you spot or if you have additional points that might be enlightening.
Given this is Google Scholar, where people figure things out by trial
and error and/or things are always in flux, it's almost certain I got
some things wrong.
Do let me know any errors you spot or if you have additional points that might be enlightening.
Musings about librarianship: 8 surprising things I learnt about Google Scholar